请使用QQ关联注册PLM之家,学习更多关于内容,更多精彩原创视频供你学习!
您需要 登录 才可以下载或查看,没有账号?注册

x
由于查找是使用最为频繁的功能之一,string 提供了非常丰富的查找函数。其列表如下:
9 n# M# J: m8 M. d6 U函数名 | 描述 | | find | 查找 | | rfind | 反向查找 | | find_first_of | 查找包含子串中的任何字符,返回第一个位置 | | find_first_not_of | 查找不包含子串中的任何字符,返回第一个位置 | | find_last_of | 查找包含子串中的任何字符,返回最后一个位置 | | find_last_not_of | 查找不包含子串中的任何字符,返回最后一个位置 |
Y! r: {. J4 i5 H/ Z7 c4 R9 j+ o
以上函数都是被重载了4次,以下是以find_first_of 函数为例说明他们的参数,其他函数和其参数一样,也就是说总共有24个函数。% G7 u' c; r z: W! x4 a
" `* O' O- h- q/ M7 r! R* \% e/ S. y1 E5 I
- size_type find_first_of(const basic_string& s, size_type pos = 0)
- size_type find_first_of(const charT* s, size_type pos, size_type n)
- size_type find_first_of(const charT* s, size_type pos = 0)
- size_type find_first_of(charT c, size_type pos = 0) ' v7 U% \3 [6 V+ m4 o( m' C, }. u
" t+ O" W2 [1 ?4 `) m
size_type find_first_of(const basic_string& s, size_type pos = 0)size_type find_first_of(const charT* s, size_type pos, size_type n)size_type find_first_of(const charT* s, size_type pos = 0)size_type find_first_of(charT c, size_type pos = 0) ( f) K( N6 b6 W8 O6 {0 X
7 q# m8 A& v" p' e$ p
所有的查找函数都返回一个size_type类型,这个返回值一般都是所找到字符串的位置,如果没有找到,则返回string::npos。有一点需要特别注意,所有和string::npos的比较一定要用string::size_type来使用,不要直接使用int 或者unsigned int等类型。其实string::npos表示的是-1, 看看头文件:' p8 h0 |# A F( V" E) Y; C5 M3 F
3 s }* G: Y' s& @: r
% q l8 i8 \. Q6 u- template <class _CharT, class _Traits, class _Alloc>
- const basic_string<_CharT,_Traits,_Alloc>::size_type
- basic_string<_CharT,_Traits,_Alloc>::npos
- = basic_string<_CharT,_Traits,_Alloc>::size_type) -1;
% F/ J$ r; Q4 G# q
8 i* n& q# [8 q
template <class _CharT, class _Traits, class _Alloc> const basic_string<_CharT,_Traits,_Alloc>::size_type basic_string<_CharT,_Traits,_Alloc>::npos = basic_string<_CharT,_Traits,_Alloc>::size_type) -1; ' D4 t. T. L- E1 Z0 ?/ f0 O
8 x( X2 i' Y) _6 A8 _6 p8 x6 ^" U! K9 c, q
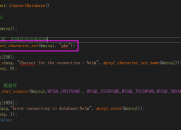
find 和 rfind 都还比较容易理解,一个是正向匹配,一个是逆向匹配,后面的参数pos都是用来指定起始查找位置。对于find_first_of 和find_last_of 就不是那么好理解。 find_first_of 是给定一个要查找的字符集,找到这个字符集中任何一个字符所在字符串中第一个位置。或许看一个例子更容易明白。 有这样一个需求:过滤一行开头和结尾的所有非英文字符。看看用string 如何实现: 6 h# b \( d0 A& L0 _
0 c' J" h& G. R9 ~2 d( R- #include <string>
- #include <iostream>
- using namespace std;
- int main(){
- string strinfo=" //*---Hello Word!......------";
- string strset="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz";
- int first = strinfo.find_first_of(strset);
- if(first == string::npos) {
- cout<<"not find any characters"<<endl;
- return -1;
- }
- int last = strinfo.find_last_of(strset);
- if(last == string::npos) {
- cout<<"not find any characters"<<endl;
- return -1;
- }
- cout << strinfo.substr(first, last - first + 1)<<endl;
- return 0;
- } + ]5 i, L ~: R* q4 ]
6 ]+ c( ~1 s4 E: h; v. J Z1 z
#include <string>#include <iostream>using namespace std;int main(){ string strinfo=" //*---Hello Word!......------"; string strset="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; int first = strinfo.find_first_of(strset); if(first == string::npos) { cout<<"not find any characters"<<endl; return -1; } int last = strinfo.find_last_of(strset); if(last == string::npos) { cout<<"not find any characters"<<endl; return -1; } cout << strinfo.substr(first, last - first + 1)<<endl; return 0;}
* X% e) j; `6 |- e1 x" ^# `+ n+ J! y3 n1 N2 P
: I7 v7 E M S1 M ~
5 o5 e* r6 a+ ?0 k: f, Z |









 |小黑屋|PLM之家-专注工业软件生态建设,大模型CAD创新生态
|小黑屋|PLM之家-专注工业软件生态建设,大模型CAD创新生态





 发表于 2014-3-9 12:47:32
发表于 2014-3-9 12:47:32


