|
|
请使用QQ关联注册PLM之家,学习更多关于内容,更多精彩原创视频供你学习!
您需要 登录 才可以下载或查看,没有账号?注册

x
之所以抛弃char*的字符串而选用C++标准程序库中的string类,是因为他和前者比较起来,不必 担心内存是否足够、字符串长度等等,而且作为一个类出现,他集成的操作函数足以完成我们大多数情况下(甚至是100%)的需要。我们可以用 = 进行赋值操作,== 进行比较,+ 做串联(是不是很简单?)。我们尽可以把它看成是C++的基本数据类型。& o) E2 L% e: Z7 w/ ~% U R' s
1 W4 Y9 h" f. ?, l! S* H首先,为了在我们的程序中使用string类型,我们必须包含头文件 <string>。如下:. _8 Y7 l* r5 R1 w; H' v
#include <string> //注意这里不是string.h string.h是C字符串头文件
4 J) R; T" ~+ P) I6 }
" f1 L2 b$ l8 ~ g! ?5 y+ M1.声明一个C++字符串1 s1 g% X+ E2 [; C
声明一个字符串变量很简单:
2 m. s! g+ H7 n* ?* s2 y string Str;4 M F% g9 ]; o" O" ^! Z
这样我们就声明了一个字符串变量,但既然是一个类,就有构造函数和析构函数。上面的声明没有传入参数,所以就直接使用了string的默认的构造函数,这个函数所作的就是把Str初始化为一个空字符串。String类的构造函数和析构函数如下:8 o! G; C7 k1 I* P+ V
a) string s; //生成一个空字符串s
! S: V* W" b7 {! wb) string s(str) //拷贝构造函数 生成str的复制品
9 ]6 B# S8 d; Wc) string s(str,stridx) //将字符串str内"始于位置stridx"的部分当作字符串的初值
. k0 M8 J9 C* r) {- ^d) string s(str,stridx,strlen) //将字符串str内"始于stridx且长度顶多strlen"的部分作为字符串的初值- ?/ W$ f# F2 j$ E$ H, x* D
e) string s(cstr) //将C字符串作为s的初值7 h/ v# Y: R/ `8 n7 k
f) string s(chars,chars_len) //将C字符串前chars_len个字符作为字符串s的初值。" n% y( {! c& a. l/ U
g) string s(num,c) //生成一个字符串,包含num个c字符2 Y+ @+ _2 Q# U; J5 N; X; @
h) string s(beg,end) //以区间beg;end(不包含end)内的字符作为字符串s的初值# b0 E5 m0 f* i! R+ f7 X
i) s.~string() //销毁所有字符,释放内存2 b: s. o8 m; \6 p% _( D6 f
都很简单,我就不解释了。" L* [& C4 j1 _/ j! j) c# R0 l9 T
/ f; Y# B* Z2 _" @
2.字符串操作函数 w+ \ O' o+ i1 d' a% T
这里是C++字符串的重点,我先把各种操作函数罗列出来,不喜欢把所有函数都看完的人可以在这里找自己喜欢的函数,再到后面看他的详细解释。+ \1 M9 Y2 B7 I v, ?4 J
a) =,assign() //赋以新值
6 O0 }9 L7 Z& X* C) q1 }% n0 [$ fb) swap() //交换两个字符串的内容
: s8 S, h/ \* `c) +=,append(),push_back() //在尾部添加字符
; i. q- H7 z6 X2 s. q# `/ ^1 kd) insert() //插入字符
, g2 z5 V8 ?5 |! Ge) erase() //删除字符
- k) e$ c! h3 `0 r" t4 E+ yf) clear() //删除全部字符" W7 a7 V& b, D
g) replace() //替换字符
/ _# J- u# H& G4 w- G& Ph) + //串联字符串) f1 A( O. H, U |" i
i) ==,!=,<,<=,>,>=,compare() //比较字符串4 a1 r6 `1 }7 r0 j- U0 \' i( ]
j) size(),length() //返回字符数量1 _! G4 {, Y, v- J! ?7 c
k) max_size() //返回字符的可能最大个数
7 d) c! T$ k+ w% s3 n( f1 Tl) empty() //判断字符串是否为空( q8 ^3 L) q/ X. Q0 r$ D2 B
m) capacity() //返回重新分配之前的字符容量
9 u" V/ q5 v9 v% A" Xn) reserve() //保留一定量内存以容纳一定数量的字符# m6 x1 i$ g' e, ?2 ^' d8 o
o) [ ], at() //存取单一字符
+ t; E# N2 C7 u* s' Mp) >>,getline() //从stream读取某值
& s5 I' t5 _( N) b8 ~q) << //将谋值写入stream% d% Z5 J0 ]3 }, Q
r) copy() //将某值赋值为一个C_string
6 _1 G3 u4 h% Y) {3 C& T- O- d! bs) c_str() //将内容以C_string返回
% a, R, i; U, kt) data() //将内容以字符数组形式返回" Q- L' [4 o! j1 a5 j4 G
u) substr() //返回某个子字符串
% i3 T* A! d6 B* z$ ^$ ^, Av)查找函数
: q. F9 A0 S; C( cw)begin() end() //提供类似STL的迭代器支持1 k! k' L& g% [$ h
x) rbegin() rend() //逆向迭代器
" j, t: |' V( B2 t i. uy) get_allocator() //返回配置器# C+ C; \+ X4 G* I
下面详细介绍:. ]2 _4 Q0 R; Y: ]$ d9 y5 U
9 }' J" V5 H# w" M2.1 C++字符串和C字符串的转换
( ^3 p9 Z3 M; q7 P3 q3 E* E+ B C ++提供的由C++字符串得到对应的C_string的方法是使用data()、c_str()和copy(),其中,data()以字符数组的形式返回字符串内容,但并不添加’\0’。c_str()返回一个以‘\0’结尾的字符数组,而copy()则把字符串的内容复制或写入既有的c_string或 字符数组内。C++字符串并不以’\0’结尾。我的建议是在程序中能使用C++字符串就使用,除非万不得已不选用c_string。由于只是简单介绍,详细介绍掠过,谁想进一步了解使用中的注意事项可以给我留言(到我的收件箱)。我详细解释。
6 n: D/ z* q5 P) ? 6 t, S6 v& L1 c
2.2 大小和容量函数
5 c; P( h7 ^# j( U2 U4 O; p8 k# f 一个C++字符 串存在三种大小:a)现有的字符数,函数是size()和length(),他们等效。Empty()用来检查字符串是否为空。b)max_size() 这个大小是指当前C++字符串最多能包含的字符数,很可能和机器本身的限制或者字符串所在位置连续内存的大小有关系。我们一般情况下不用关心他,应该大小足够我们用的。但是不够用的话,会抛出length_error异常c)capacity()重新分配内存之前 string所能包含的最大字符数。这里另一个需要指出的是reserve()函数,这个函数为string重新分配内存。重新分配的大小由其参数决定, 默认参数为0,这时候会对string进行非强制性缩减。
3 G$ W0 K: a: C' |+ Z, |
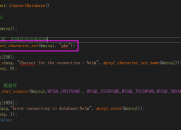
# X4 c* j2 g& [8 w+ ]6 _还有必要再重复一下C++字符串和C字符串转换的问 题,许多人会遇到这样的问题,自己做的程序要调用别人的函数、类什么的(比如数据库连接函数Connect(char*,char*)),但别人的函数参 数用的是char*形式的,而我们知道,c_str()、data()返回的字符数组由该字符串拥有,所以是一种const char*,要想作为上面提及的函数的参数,还必须拷贝到一个char*,而我们的原则是能不使用C字符串就不使用。那么,这时候我们的处理方式是:如果 此函数对参数(也就是char*)的内容不修改的话,我们可以这样Connect((char*)UserID.c_str(), (char*)PassWD.c_str()),但是这时候是存在危险的,因为这样转换后的字符串其实是可以修改的(有兴趣地可以自己试一试),所以我强调除非函数调用的时候不对参数进行修改,否则必须拷贝到一个char*上去。当然,更稳妥的办法是无论什么情况都拷贝到一个char*上去。同时我们也祈 祷现在仍然使用C字符串进行编程的高手们(说他们是高手一点儿也不为过,也许在我们还穿开裆裤的时候他们就开始编程了,哈哈…)写的函数都比较规范,那样 我们就不必进行强制转换了。( O7 M8 \6 p; q/ b
2.3元素存取, H7 K* k9 T: H
9 x2 {* {+ u' \
我们可以使用下标操作符[]和函数at()对元素包含的字符进行访问。但是应该注意的是操作符[]并不检查索引是否有效(有效索引0~str.length()),如果索引失效,会引起未定义的行为。而at()会检查,如果使用 at()的时候索引无效,会抛出out_of_range异常。
: Y5 T/ N7 ~7 y# W0 y 有一个例外不得不说,const string a;的操作符[]对索引值是a.length()仍然有效,其返回值是’\0’。其他的各种情况,a.length()索引都是无效的。举例如下:
" L4 R) l+ X# i0 }const string Cstr("const string");
) G6 A& H3 |2 s2 ^% Ystring Str("string");
7 q- N0 b j+ {# p+ Q
4 h1 |' y. s0 S* ~1 O0 G8 p# Q: |Str[3]; //ok
) ?% U* C. s- e4 e6 H: @Str.at(3); //ok
! m6 T8 s& P4 |: l( \" |* M * b* W; l, g& ^9 M5 S+ J) U
Str[100]; //未定义的行为% @3 _0 O; [8 W7 x/ ?4 R( W
Str.at(100); //throw out_of_range
, G, o: q( i+ T. X% J! ^5 |
' ]' D" o/ R1 W# p& y! w2 S7 o9 LStr[Str.length()] //未定义行为
$ n3 Z( y( K& nCstr[Cstr.length()] //返回 ‘\0’
! @/ k* a. v jStr.at(Str.length());//throw out_of_range% J/ j* R4 r; R& u9 r5 T ^. x
Cstr.at(Cstr.length()) ////throw out_of_range0 ~2 K. K* o, X2 E# y2 m( |
$ \& i* r' q' e: x: |% H我不赞成类似于下面的引用或指针赋值:
) q, w3 j6 @' t7 Y# k9 y& Fchar& r=s[2];
9 d5 H' [: x( f7 u5 \char* p= &s[3];
: X/ T N; b4 O( `# d W因为一旦发生重新分配,r,p立即失效。避免的方法就是不使用。
: k4 i; m0 |& R t V
* i; n9 ?1 @0 M" ^2.4比较函数" E' U) q! w( s5 L& d- k' X6 Z
C ++字符串支持常见的比较操作符(>,>=,<,<=,==,!=),甚至支持string与C-string的比较(如 str<"hello")。在使用>,>=,<,<=这些操作符的时候是根据"当前字符特性"将字符按字典顺序进行逐一得 比较。字典排序靠前的字符小,比较的顺序是从前向后比较,遇到不相等的字符就按这个位置上的两个字符的比较结果确定两个字符串的大小。同时,string ("aaaa") <string(aaaaa)。/ B8 K1 r+ ]9 S8 z c5 T$ R- P7 u
另一个功能强大的比较函数是成员函数compare()。他支持多参数处理,支持用索引值和长度定位子串来进行比较。他返回一个整数来表示比较结果,返回值意义如下:0-相等 〉0-大于 <0-小于。举例如下:
i9 E# n! K6 X( ~3 a1 v5 q string s("abcd");0 i7 h `+ X% e; t) H @$ L
9 }4 L' Y5 i! [5 D/ o/ H s.compare("abcd"); //返回0
$ x, Y' Q3 _" a4 t4 e s.compare("dcba"); //返回一个小于0的值
& Y7 [; G4 c0 t s.compare("ab"); //返回大于0的值4 H9 a- O( j, o- |3 _2 E
2 R5 T( H( S9 ?8 m
s.compare(s); //相等
: X. M+ h) j) s- `$ h! n% M- K s.compare(0,2,s,2,2); //用"ab"和"cd"进行比较 小于零4 N9 _. w: H2 G% X; s) _
s.compare(1,2,"bcx",2); //用"bc"和"bc"比较。
1 S; ^- h, J) l9 R" T K$ W6 I怎么样?功能够全的吧!什么?还不能满足你的胃口?好吧,那等着,后面有更个性化的比较算法。先给个提示,使用的是STL的比较算法。什么?对STL一窍不通?靠,你重修吧!
% U2 N8 C2 |5 h: @# k , f5 L7 A# l+ Z$ x2 {
2.5 更改内容0 ], m1 {4 C7 T5 {" k! j a
这在字符串的操作中占了很大一部分。
) z- O# K& J$ ?( T8 w0 l5 j) b7 F5 l 3 K+ q: P, ^7 b5 V0 c6 X# S
首先讲赋值,第一个赋值方法当然是使用操作符=,新值可以是string(如:s=ns) 、c_string(如:s="gaint")甚至单一字符(如:s=’j’)。还可以使用成员函数assign(),这个成员函数可以使你更灵活的对字符串赋值。还是举例说明吧:
|& G2 \9 T: l- _) c4 {( js.assign(str); //不说, j: i1 @) ]; L3 z/ y! ~
s.assign(str,1,3);//如果str是"iamangel" 就是把"ama"赋给字符串
; p8 A* f$ ?; w* n. T# Is.assign(str,2,string::npos);//把字符串str从索引值2开始到结尾赋给s7 V( [/ ^9 |6 O
s.assign("gaint"); //不说' U1 O, f1 |2 k% P ^9 Q
s.assign("nico",5);//把’n’ ‘I’ ‘c’ ‘o’ ‘\0’赋给字符串
' y# \2 a( f: k$ a3 j5 A% k [' Ms.assign(5,’x’);//把五个x赋给字符串2 y0 ]% S: ?) F4 b
把字符串清空的方法有三个:s="";s.clear();s.erase();(我越来越觉得举例比说话让别人容易懂!)。
* ~$ n# X. K s; i* @, j2 mstring提供了很多函数用于插入(insert)、删除(erase)、替换(replace)、增加字符。
8 [" C0 m8 T9 u先说增加字符(这里说的增加是在尾巴上),函数有 +=、append()、push_back()。举例如下:$ T$ a( M+ Q/ L5 _
s+=str;//加个字符串: U! Y. E0 _! {
s+="my name is jiayp";//加个C字符串
3 ~8 p7 ^2 H; [2 Ks+=’a’;//加个字符
; K2 n5 V, Y3 g9 p 9 S( h4 h& W8 i. d. O4 ^
s.append(str); s! X: i* D3 l$ z4 _+ A6 N
s.append(str,1,3);//不解释了 同前面的函数参数assign的解释3 m* p3 `8 [& v4 J! H8 g `
s.append(str,2,string::npos)//不解释了2 w; b, K/ I, R
4 ^/ a0 {7 Y! |* ?# K- ?8 Y* b: S& x
s.append("my name is jiayp");( l, d) a/ e" w9 q0 ^
s.append("nico",5);# c; r2 B1 o# y( f& Q
s.append(5,’x’);7 w4 [% d4 a4 h8 |0 O
3 O5 g9 p; S+ S; l* }: A
s.push_back(‘a’);//这个函数只能增加单个字符 对STL熟悉的理解起来很简单
4 @1 Q3 A% p$ ^( [( s4 n $ D. [8 Q& c5 t( K% J
也许你需要在string中间的某个位置插入字符串,这时候你可以用insert()函数,这个函数需要你指定一个安插位置的索引,被插入的字符串将放在这个索引的后面。
/ V* l9 m# [* K$ ]7 ] s.insert(0,"my name");
3 d, [& G5 e$ `- l" \4 D' I s.insert(1,str);
, o- S A6 e9 a3 U6 I$ Y' p这 种形式的insert()函数不支持传入单个字符,这时的单个字符必须写成字符串形式(让人恶心)。既然你觉得恶心,那就不得不继续读下面一段话:为了插 入单个字符,insert()函数提供了两个对插入单个字符操作的重载函数:insert(size_type index,size_type num,chart c)和insert(iterator pos,size_type num,chart c)。其中size_type是无符号整数,iterator是char*,所以,你这么调用insert函数是不行的:insert(0,1, ’j’);这时候第一个参数将转换成哪一个呢?所以你必须这么写:insert((string::size_type)0,1,’j’)!第二种形式指 出了使用迭代器安插字符的形式,在后面会提及。顺便提一下,string有很多操作是使用STL的迭代器的,他也尽量做得和STL靠近。
2 K" c8 d2 k) P删除函数erase()的形式也有好几种(真烦!),替换函数replace()也有好几个。举例吧:- J8 o, U# r. j$ c
string s="il8n";1 ~& r* B1 D1 C) k. ~9 e. }" D4 r
s.replace(1,2,"nternationalizatio");//从索引1开始的2个替换成后面的C_string4 m! w2 [" ~' W3 G, Z4 ^0 ?. y
s.erase(13);//从索引13开始往后全删除
- [' }2 i5 K( {7 e# _+ Js.erase(7,5);//从索引7开始往后删5个
4 ~- r2 u) ]0 Y# t$ n; W! r8 X
* {$ [& c& d) K, d2 g O2.6提取子串和字符串连接& v' d. `7 X+ {7 q8 \
题取子串的函数是:substr(),形式如下:% f3 k, V1 }* S; z$ C
s.substr();//返回s的全部内容
" a8 }6 Q5 G! B6 @, As.substr(11);//从索引11往后的子串7 N# D% J( P# n
s.substr(5,6);//从索引5开始6个字符
" E/ o( e0 Q9 T" ]/ z& E( b! r! L把两个字符串结合起来的函数是+。(谁不明白请致电120)0 B# K+ W" N7 @: a
& M z- e; K( ~, n
2.7输入输出操作
* l* Q! P3 I0 K4 G' ?$ K1.>> 从输入流读取一个string。
4 `1 [- i& V8 L: Y! T2.<< 把一个string写入输出流。; S, {" G, M& r$ a8 w; s$ x
另一个函数就是getline(),他从输入流读取一行内容,直到遇到分行符或到了文件尾。; g. i8 Z9 g& m" O, z- J
5 Z6 E# v$ N% ?' n" A2.8搜索与查找
6 m9 G7 n! X& ]! D. y查找函数很多,功能也很强大,包括了:
* r# h) w" _" U) C% [5 @5 C- p) b/ j find()- r! F$ w8 V8 }( |4 Q
rfind()
# w4 [. v, h: V- w) ` find_first_of()0 d9 p4 v* T, `5 U7 E% q) Z
find_last_of()
0 D" W9 H+ H3 s: ` find_first_not_of()
! E" l3 N5 A) W% ?& u$ L" c find_last_not_of()+ _5 W, B$ B4 u0 {
这些函数返回符合搜索条件的字符区间内的第一个字符的索引,没找到目标就返回npos。所有的函数的参数说明如下:
& k( u0 a9 w& ^$ [2 d第一个参数是被搜寻的对象。第二个参数(可有可无)指出string内的搜寻起点索引,第三个参数(可有可无)指出搜寻的字符个数。比较简单,不多说不理解的可以向我提出,我再仔细的解答。当然,更加强大的STL搜寻在后面会有提及。
8 R! `$ V. i1 B. ?最 后再说说npos的含义,string::npos的类型是string::size_type,所以,一旦需要把一个索引与npos相比,这个索引值必须是string::size)type类型的,更多的情况下,我们可以直接把函数和npos进行比较(如:if(s.find("jia")== string::npos))。 |
|









 |小黑屋|PLM之家-专注工业软件生态建设,大模型CAD创新生态
|小黑屋|PLM之家-专注工业软件生态建设,大模型CAD创新生态







 发表于 2013-10-22 07:19:37
发表于 2013-10-22 07:19:37


